Neo4j
Prerequisites
This tutorial expects familiarity with Neo4j querying fundamentals. Qarbine interacts with Neo4j using the Cypher querying language enabling access to Neo4j’s diverse graph database features. There are querying tutorials available and a good starting point is the page at https://neo4j.com/docs/getting-started/appendix/tutorials/tutorials-overview/.
Overview
This tutorial covers aspects of Qarbine and fundamental use of the Cypher querying language and answer set handling. Further query interaction information can be found by navigating to the Tools tab

Then, selecting the categories shown below.


Defining a Data Source
Overview
A Data Source is a Qarbine component responsible for retrieving data from somewhere. At a high level it has a name, a description and some arbitrary query string which when sent to the associated Qarbine Data Service endpoint returns some data. The overall execution flow for an analysis, including the optional prompt component, is shown below.

A single data source can be referenced by name from multiple Qarbine template components. This enables a single point of change when perhaps, an index is added, or some other query tweak is necessary. The alternative is to attempt to find all templates impacted by a schema or index change for example. This component reusability is especially beneficial when team members have varying roles and skills.
Example
Neo4j provides an online database with a movie dataset already loaded. That dataset also has embedded as well which is handy for testing out vector queries.
The standard options to choose are shown below.

The following query specification below retrieves movies Sean Connery acted in.
MATCH (a:Person {name: "Sean Connery"})-[:ACTED_IN]->(m:Movie)
RETURN m
ORDER BY m.title
A snippet of the results is shown below.

The line of the query “Return m” returns the complete label object. Selecting the “Diamonds Are Forever” row populates the right hand side with the details of that row as shown below.
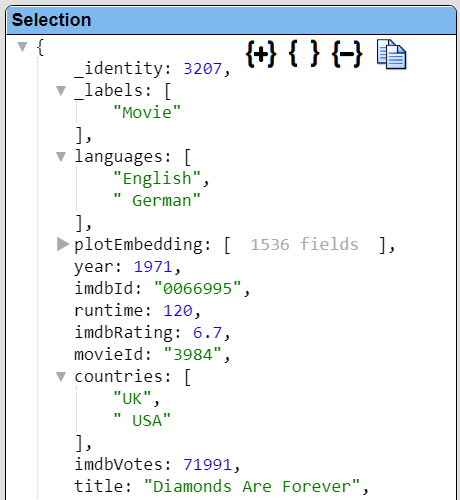 | 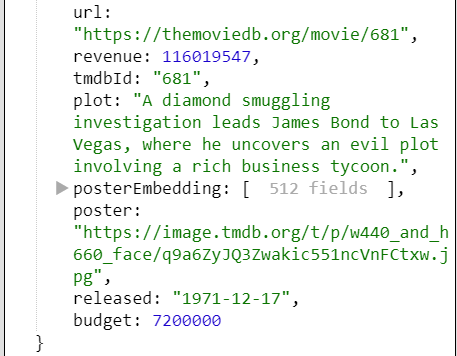 |
This data source is in the catalog at “example/Neo4j/Movie AI/Movies with Sean Connery”.
The plot embedding and posterEmbedding values are for use by vector queries. They are pretty bulky, mainly used for querying and not very useful to have in the answer set. We can remove them and a few other fields from the answer set by using a Qarbine “pragma” as shown below. An alternative is to adjust the “RETURN” statement.
The adjusted query is shown below.
#pragma deleteFields plotEmbedding, posterEmbedding, _labels, languages
#pragma deleteFields _identity, imdbId, tmdbId
MATCH (a:Person {name: "Sean Connery"})-[:ACTED_IN]->(m:Movie)
RETURN m
ORDER BY m.title
Running this and selecting “Diamonds Area Forever” now shows the following.
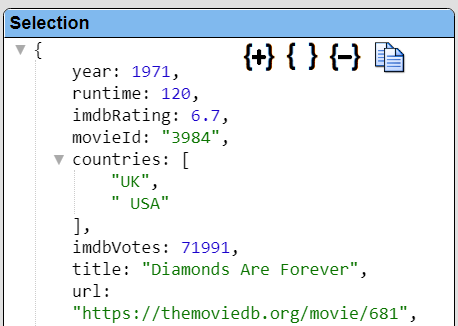 | 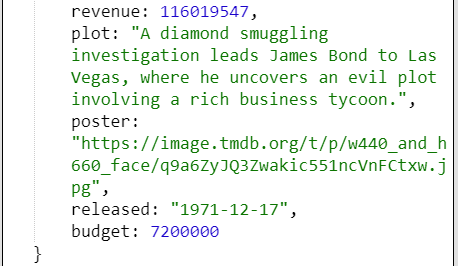 |
Notice the countries are an embedded list of strings. Qarbine handles such object structures quite easily.
This data source is in the catalog at “example/Neo4j/Movie AI/Movies with Sean Connery simplified”.
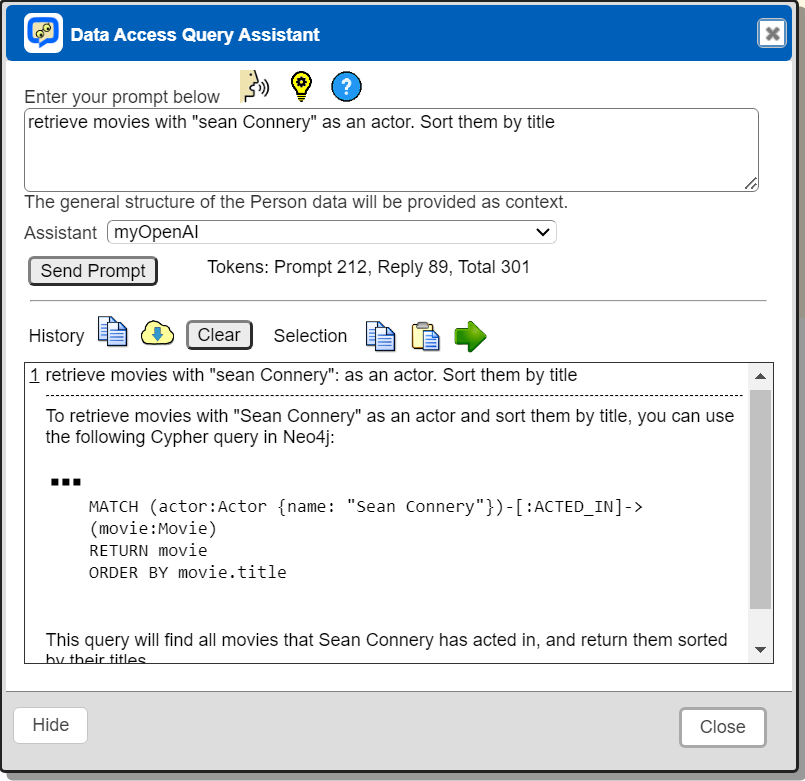
Asking AI for Cypher Assistance
Cypher can be a bit complex at times. If your Qarbine installation is configured with AI Assistants, then click on

This opens the dialog as shown below which includes the results of “Asking AI”.
Managing Answer Set Size
The default maximum number of rows starts off at 25 for a new data source. This is useful to evolve a query from a concept to one that you have verified returns the desired answer set. As noted, any native way of limiting an answer set size is the preferred approach. This setting is in the component dialog as shown below and also accessible by clicking the ‘Gear’ icon.
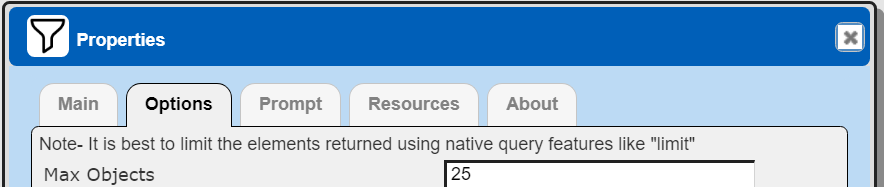
Once you are done drafting you can adjust this parameter. A “0” indicates there is no maximum. A number greater than 0 indicates to limit the final answer set size to that number of rows. This answer set truncation comes after any native query limit. So, if the answer set from the data endpoint is quite large, that content has to be returned to the Qarbine host. It then may truncate the number of rows. It is best to truncate at the query level (i.e., use a limit) to reduce the content sent from the data endpoint to the Qarbine host in the first place.
Adjusting Maximum Rows
Recall the default maximum rows at the component level is 25. When you are satisfied with your query you can change that setting by clicking.

Adjust the setting to “0” indicating no Qarbine answer set truncation.

To close the dialog click

To keep this setting save the data source to the catalog.
Prompt Integration
Overview
Qarbine prompts provide a way to obtain runtime values and variables for data source and template execution. To avoid hardcoding, prompts can use macro formulas to run queries which populate list widgets. Prompts are defined in a no code manner using the Prompt Designer. Shown below is the execution flow when there is a Prompt component.

The Prompt Designer supports a large variety of input widgets including entry fields, check boxes, radio button groups, sliders, and file input.
Example
The Qarbine Prompt Designer supports 10+ different widget types. Below is the prompt for this example which has a heading and entry field input widget.
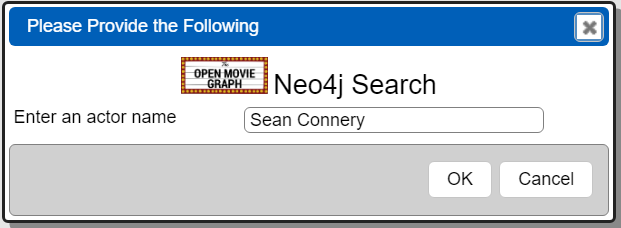
This Qarbine prompt has 2 elements as shown below.

The second one is used to capture the user’s input into the variable named “actorName". The details of this prompt can be found by reviewing it. It is located in the catalog at “example/Neo4j/Movie AI/Prompt for an actor”.
Adjusting the Data Source
The prompt sets a runtime variable named ‘@actorName which propagates along to the execution process. A new data source can be defined to use this variable value. The data source in the catalog at “example/Neo4j/Movie AI/Movies with actor @actorName” uses the following query specification.
#pragma deleteFields plotEmbedding, posterEmbedding, _labels, languages
#pragma deleteFields _identity, imdbId, tmdbId
MATCH (a:Person {name: @actorName})-[:ACTED_IN]->(m:Movie)
RETURN m
ORDER BY m.title
Clicking  to access the properties shows that it references the prompt mentioned above.
to access the properties shows that it references the prompt mentioned above.
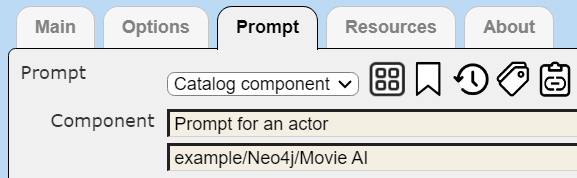
If you are following along and creating a data source, then click the recent button  to easily choose the prompt just created.
to easily choose the prompt just created.
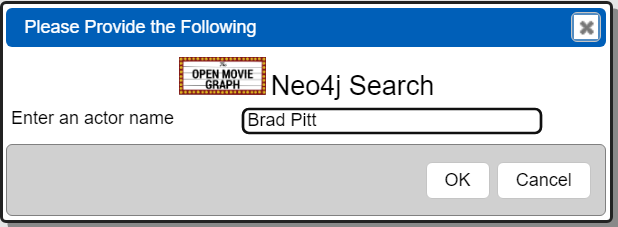
Running the data source by clicking  presents the referenced prompt to obtain user input.
presents the referenced prompt to obtain user input.
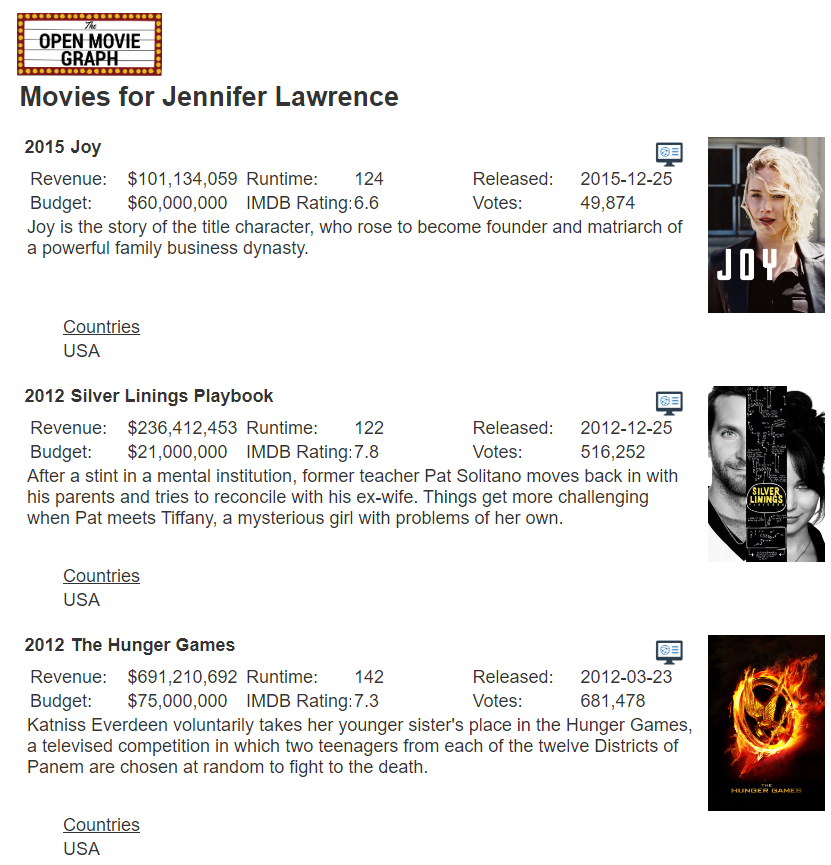
That value is inserted into the query specification to form the query sent to Neo4j. Below is a snippet of the results.

If you are following along and creating a data source, then click the “Save as” or “Save” buttons and follow the dialogs to save the component in the catalog.
This example can be found at “example/Neo4j/Movie AI/Movie search prompt”.
Defining an Analysis Template
Overview
A template defines how to process the data being retrieved from Data Source queries and other data expressions. It also defines formulas, formatting options, and other analysis and presentation options. The overall execution flow for an analysis, including the optional prompt component, is shown below

Using the Template Designer
The result of running the about to be described template is shown below.
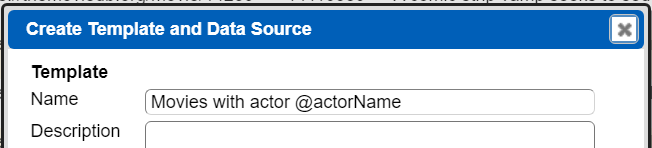
A quick way to get a head start on defining a template from a data source is to click  in the Data Source Designer. In the dialog add any description in the top half.
in the Data Source Designer. In the dialog add any description in the top half.
Optionally choose a wider page for generation.

In the bottom half be sure to blank out the field shown below.

This associates the data source by reference with the to be generated template.
Click OK, navigate to the destination folder, and then click OK again to generate the template into that folder.
An informational dialog is shown to remind you to allow popups so that the Template Designer tab can be opened.
The generated template has lots of cells and is conveniently set up to handle any embedded arrays. Usually the cells need to be re-arranged a bit, but having labels and formula cells defined saves time from manually defining them.
This example template can be found in the catalog at “example/Neo4j/Movie AI/Movies with actor @actorName”.
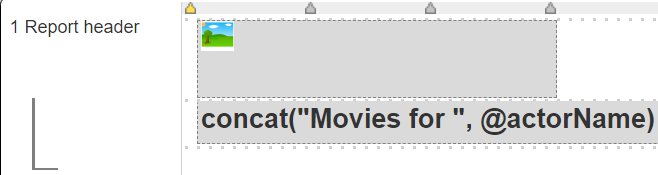
The report header uses an image cell for the “Open Movie Graph” logo and formats a heading using the @actorName variable.
Clicking where there is no cell shows the general properties of the main retrieval on the right side.
| Main Fields | Additional Fields |
|---|---|
 |  |
Notice the “countries” embedded array which is a list of simple strings. Many times the embedded arrays have more complex objects. This list is iterated through by group 1.1’s data retrieval setting. To see it right click

and select

The dialog includes the settings shown below.



Close the dialog by clicking

The core layout of the template is shown below.
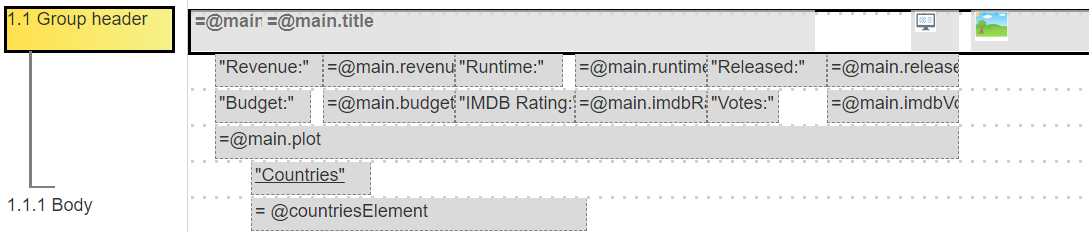
The first group header has the following cells for the year and title in bold. They are followed by a clicking URL button and the poster picture.
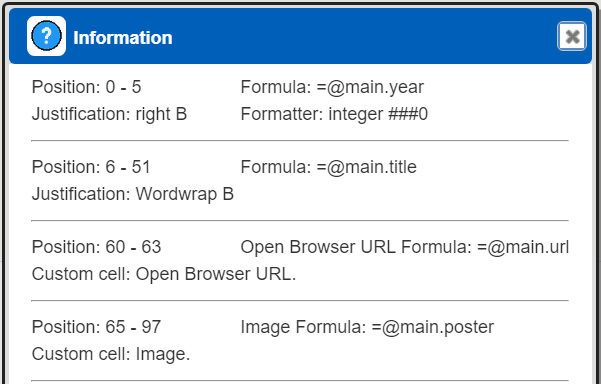
Group 1.1’s data retrieval is used to iterate through and format the country values.